갑자기 든 의문
Mongo DB 조회 성능 개선기
https://www.mongodb.com/ko-kr/docs/manual/tutorial/sort-results-with-indexes/ 복잡한 Join 탈출 - 결제 내역 조회 With Mongo DB진행중인 프로젝트에선 사용자들이 Question이라는 상품을 구매할 수 있습니다. Question은 고
e4g3r.tistory.com
위 포스팅은 MongoDB 조회 성능을 개선했던 포스팅이다.
Spring Data Mongo가 기본적으로 제공하는 Mapping Converter로 인한 병목이 원인이었다.
그래서 별도의 Custom Mapping Converter를 작성해서 병목을 줄였다.
최근에 위 포스팅을 다시 살펴보게 되었고, 다시 읽다보니 다른 의문이 생기게 되었다.
"RDB 환경에서 사용되는 Spring Data JPA + Hibernate 환경에서도 매핑으로인한 병목이 발생하고 있었던게 아닌가?"
그래서 Hibernate는 어떻게 매핑을 처리하는지, 오버헤드는 없는지 알아보게 되었다.
Hibernate의 스킬
Hibernate 입장에서는 클라이언트가 어떤 데이터를 조회할 지 모른다.
애플리케이션에서는 다양한 Entity, JpaRepository, JPQL 들이 사용될 것이다. 그리고 이러한 것들은 각각 다른 데이터를 요청한다.
UserEntity를 조회할 때에는 DB로부터 Select User from User를 하고 조회된 결과를 매핑할 것이다.
BoardEntity를 조회할 때에는 DB로부터 Select Board from Board를 하고 조회된 결과를 매핑할 것이다.
UserDto를 조회할 때에는 DB로부터 Select User.name, User.phone from User를 하고 조회된 결과를 매핑할 것이다.
따라서 Hibernate는 매 요청마다 DB로부터 전달받은 데이터를 클라이언트가 원하는 형태로 매핑하고 반환해줘야 한다.
프레임워크는 일반적으로 이런 경우를 리플랙션으로 처리한다.
리플랙션을 사용하게 되면, 런타임 시점에 전달되는 클래스 타입의 정보를 분석할 수 있다.
예를들어 어떤 필드들이 있는지, 어떠한 타입들이 있는지 말이다.
그래서 쉽게 생각해보면 Hibernate도 매 요청마다 리플랙션을 통해 어떠한 필드들을 채워넣어줘야 하는지 분석하면 문제는 없다.

하지만 리플랙션은 오버헤드가 매우 크다는 단점이 있다.
그런데 프로파일링을 해보면 막상 리플랙션으로 인한 오버헤드는 보이지 않는다.
그리고 실제로 디버깅을 해보면 리플랙션을 통해 매핑 될 객체의 타입을 살펴보는 로직도 보이지 않는다. 그럼 어떻게 하는걸까?
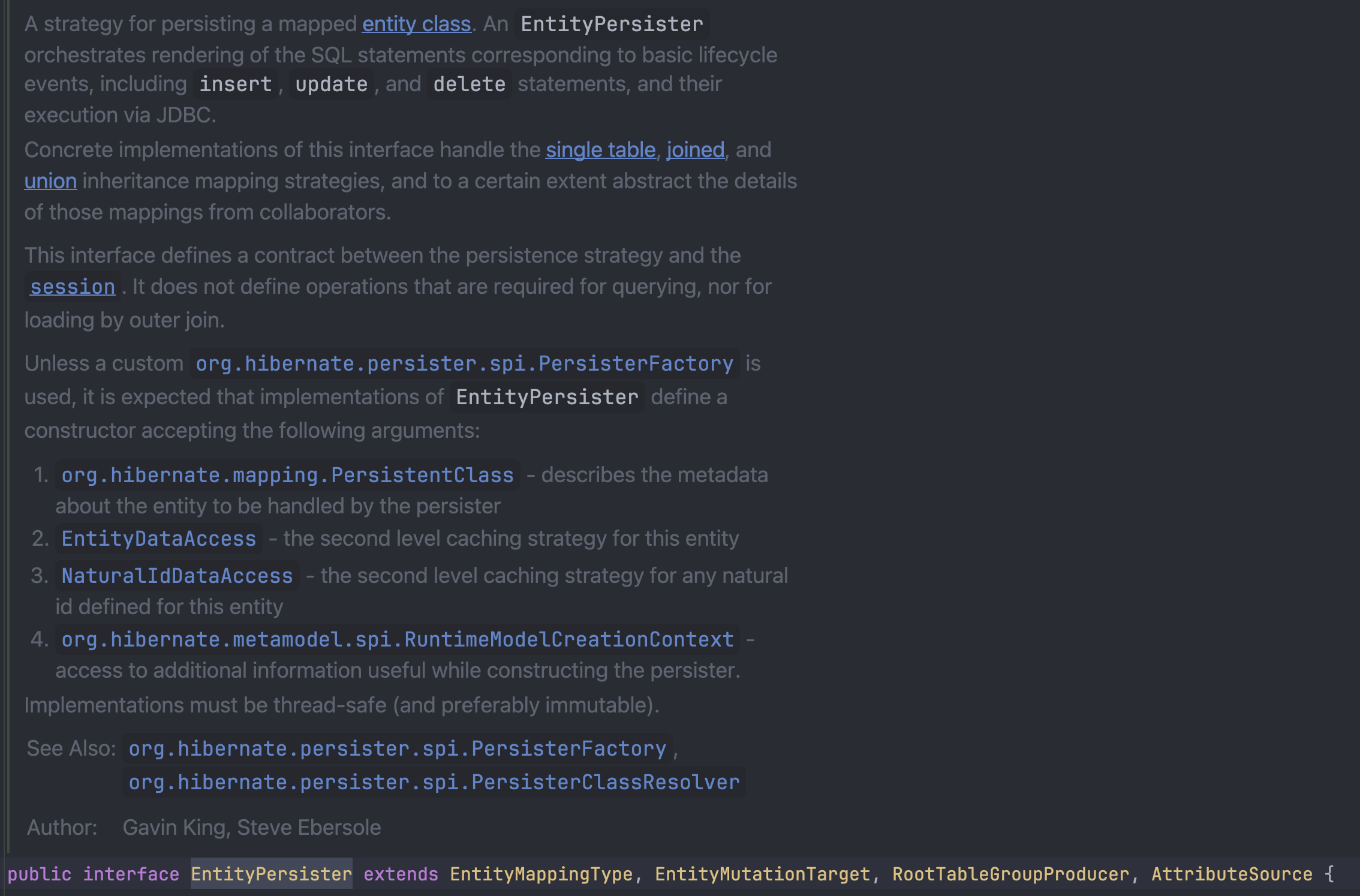
사실 스프링 애플리케이션이 시작되면 Hibernate는 Entity 클래스를 돌면서 미리 메타 정보를 수집한다.

메타 데이터는 EntityPersister로 가공되어 저장되는데 내부에 있는 필드만 봐도 많은 정보들이 있음을 알 수 있다.
이런 메타 데이터를 미리 만들어두기에 매핑을 할 때 리플랙션을 이용해서 어떠한 필드들을 채워넣어야 할지 분석하는
그런 과정이 불필요했던 것이다. 그런데 EntityPersister 그 자체로 사용하지는 않고 특정 형태로 가공해서 사용한다.
Hibernate는 JPQL을 SQL로 변환한 후, JDBC로 SQL을 전송한다. 그리고 DB로부터 전달받은 결과를 매핑해서 반환해준다.
근데 JPQL을 바로 SQL로 변환하는게 아니라 JPQL을 분석하고 분석된 정보를 SQM이라는 형태로 1차 가공을 한다.
SQM에는 어떠한 Entity 필드들이 JPQL에서 선언되고 사용되는지, 그리고 SQL로 변환하기 위한 여러 정보들이 담겨있다.
위 코드는 그렇게 만들어진 SQM을 해석해서 SQL로 변환하기 위한 준비 과정을 담당한다.

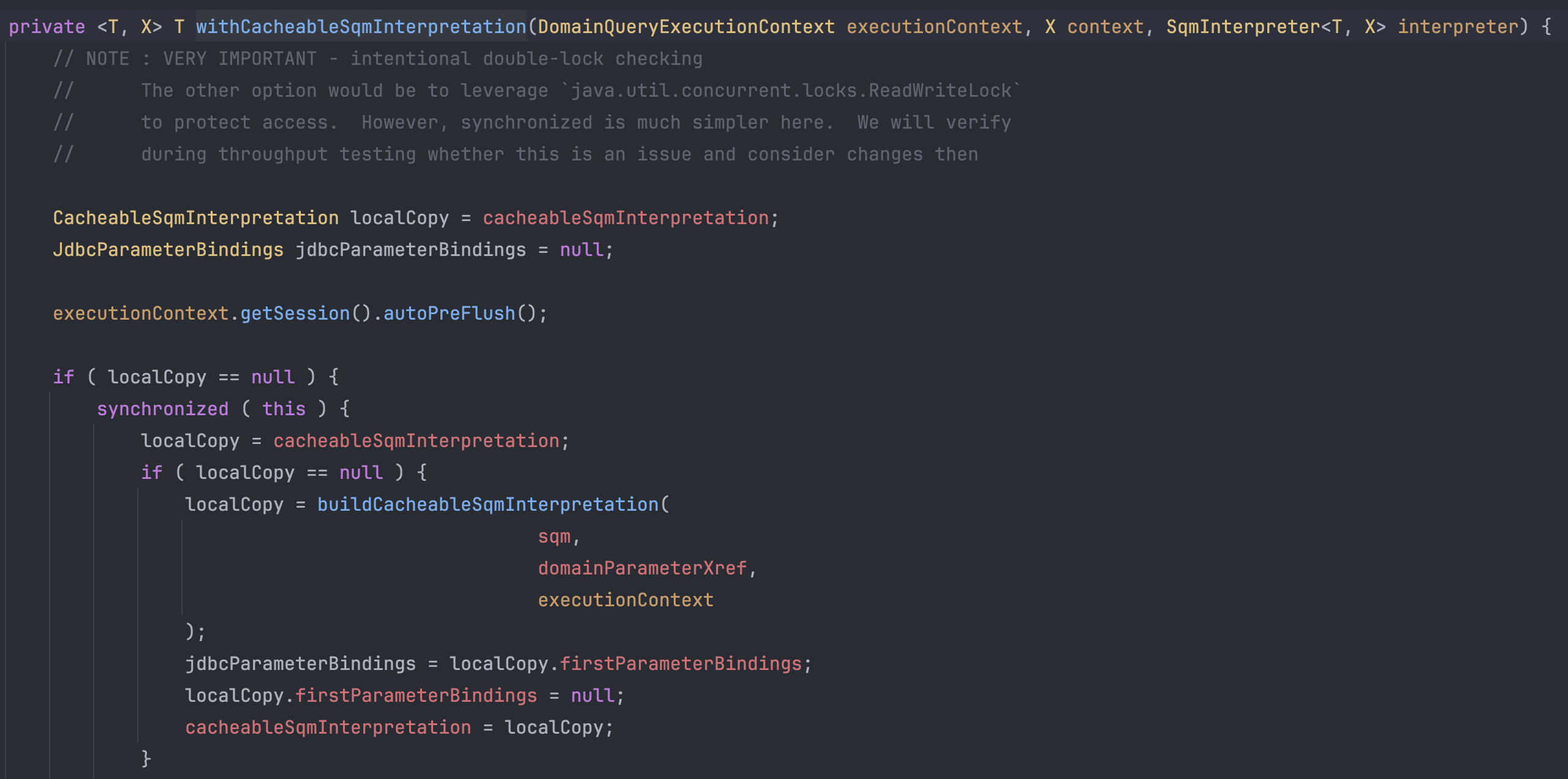
과정을 쭉 따라가다보면 CacheableSqmInterpretation 객체를 만드는 메서드를 만나게 된다.
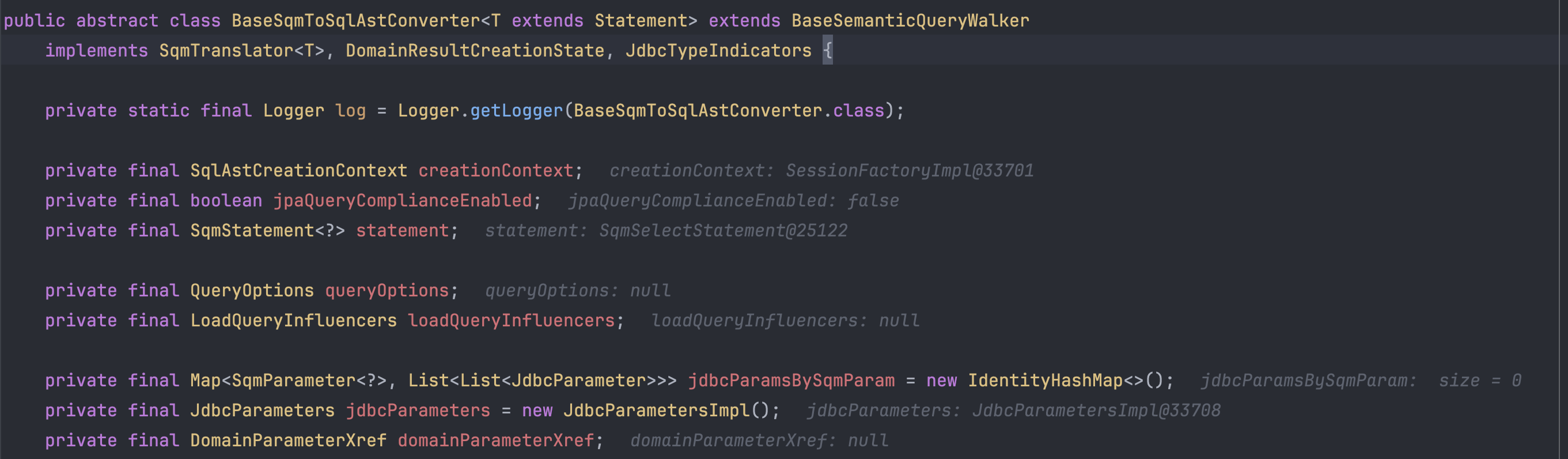
translate를 호출하게 되면 내부적으로 BaseSqmToSqlAstConverter를 사용하게 되는데 SQM 정보를 이용해서
SQL로 변한하기 위한 Converter를 생성하는 느낌이다. (코드가 복잡하니 문맥 상 흐름으로 이해하자.)

계속 진행하면 visitSelection 메서드를 만나게 되는데 이곳에서는 SQM 내부에 존재하는 정보를 순회하면서 어떤 필드, 속성들이
선택되었는지를 확인한다.
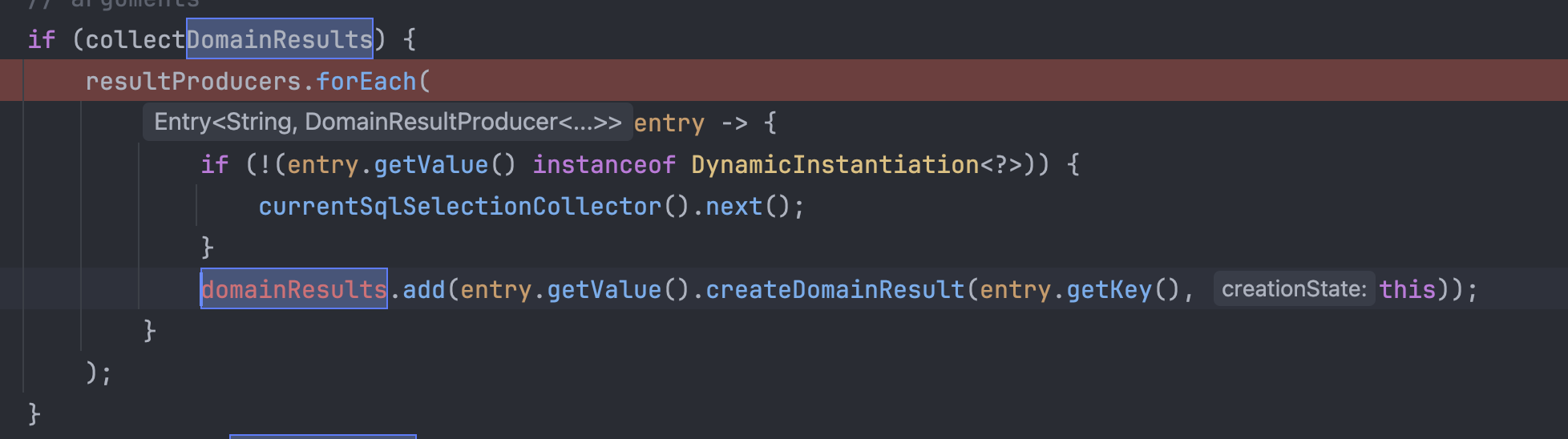
그리고 순회하고 있는 필드에 대한 domainResult라는 것을 생성하고 리스트에 추가하는 부분을 볼 수 있었다.

이 메서드가 호출하는 createDomainResult를 확인해보자.

호출되는 createDomainResult는 위에서 보았던 EntityPersister의 메서드이다.
반환 타입을 보면 DomainResult이다.
DomainResult라는 것은 인터페이스인데 조회하고자 하는 Entity 혹은 필드에 대한 정보들을 보관, 관리하는 것을 정의한다.
위에서 EntityPersister에 있는 매핑 정보를 그대로 사용하는 것이 아니라, 특정한 형태로 가공해서 사용한다고 했다.
가공되는 형태가 바로 DomainResult인 것이다.
위 코드를 보면 반환되는 구체타입은 EntityResultImpl인데 DomainResult 구현체 중 하나이며 Entity 전체를 조회할 때 사용되는 DomainResult이다. 즉 전체의 Entity를 조회하는 "Select User from User" JPQL은 EntityResultImpl를 사용하게 된다.
그럼 여기까지 내용을 정리해보자.
1. Spring 애플리케이션이 시작되면 Hibernate는 Entity 클래스를 순회하면서 Entity 클래스에 담겨있는 여러 메타 정보를
파싱해서 EntityPersister로 보관한다.
2. Hibernate는 JPQL을 분석해서 SQM이란 형태로 변환하는데, SQM에는 JPQL이 무엇을 조회하고자 하는지, 어떠한 형태로
조회하고 싶은지에 대한 정보들이 있다.
3. Hibernate는 SQM을 SQL로 변환하는 과정에서 어떻게 결과를 매핑하는지에 대한 정보도 가공하게 되는데, SQM에 있는 정보를
기반으로 조회하고자 하는 필드들을 적절하게 매핑할 수 있도록 도와주는 DomainResult를 만든다.
만들어둔 EntityPersister를 기반으로 DomainResult를 만들 수 있으며 필드 이름, 타입 정보 등이 담겨 있다.
따라서 Hibernate는 JPQL -> SQM -> DomainResult 과정을 거치면서 어떻게 DB로부터 조회를 해야하고, 그 결과를
매핑해야하는지 설계를 해두는 것이다.
DomainResult는 앞으로 모든 과정에서 핵심으로 사용된다. 그러니 꼭 기억하자.
Hibernate의 조회
그럼 이제 Hibernate가 어떻게 조회를 해서 매핑 하는지 직접 살펴보자
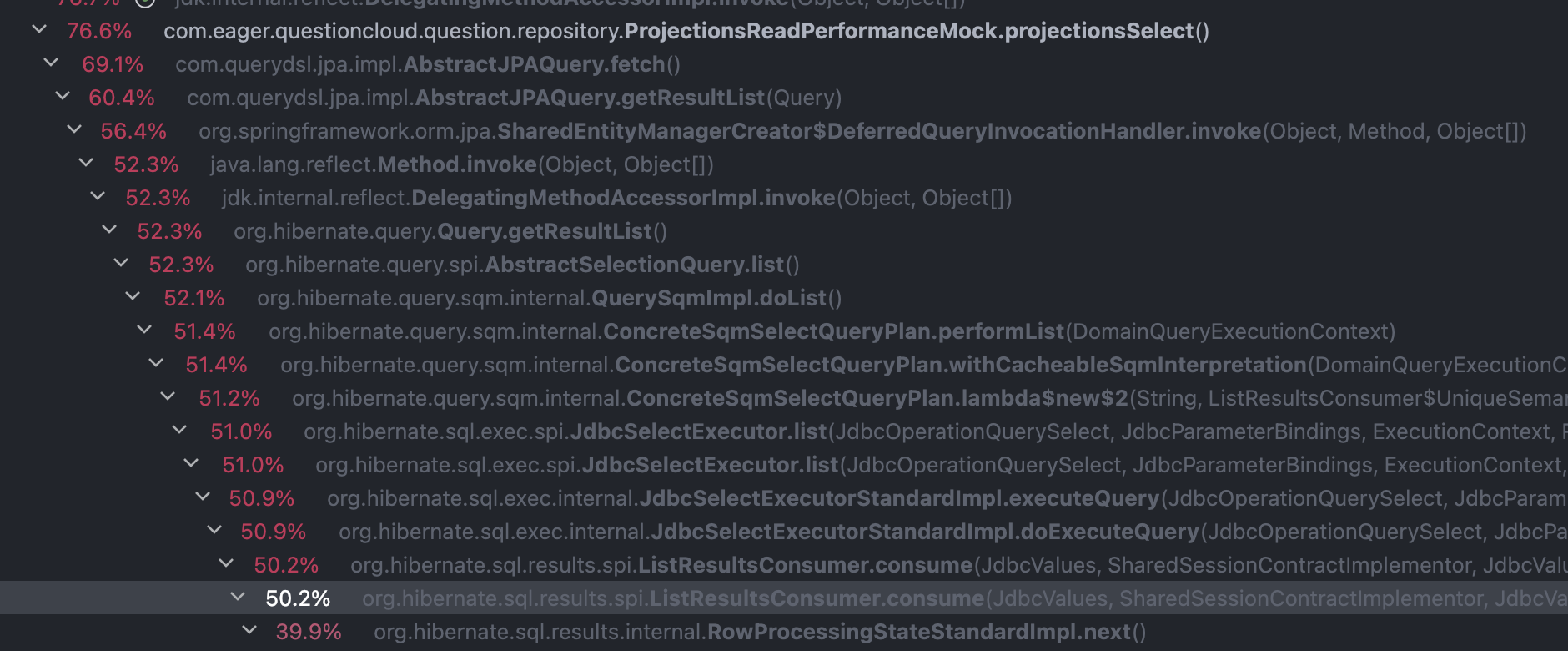
먼저 hibernate가 jpa로부터 조회를 해달라고 요청을 받게되면 위와 같은 복잡한 흐름으로 진행된다. 그렇기에 핵심 위주로 보자.

위에서 잠깐 봤던 부분이긴 한데 이 부분이 SQM으로부터 다양한 정보를 추출해서 여러 도구를 만드는 과정이다.
여기서 위에서 말했던 domainResult도 만들어지고, JDBC로 요청을 보낼 때 필요한 컨텍스트 등 들이 가공된다.
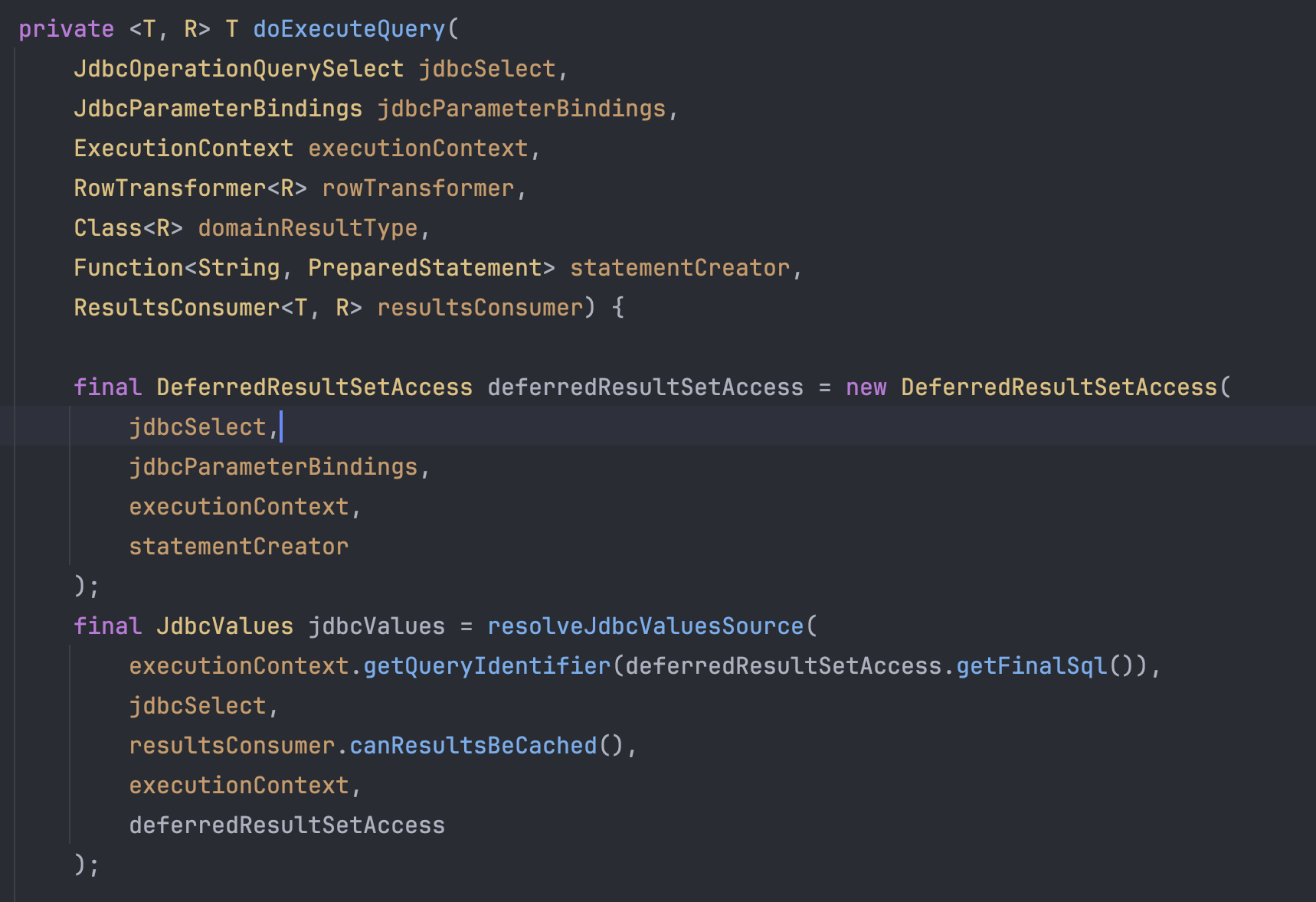
이후 위에서 가공된 데이터들은 doExecuteQuery라는 메서드의 파라미터로 전달되면서 SQL을 DB로 요청하기 위한 작업을 시작한다.
먼저 doExecutreQuery 내부에서는 처음에 객체 2개를 생성한다.

처음으로 생성하는 DeferredResultSetAccess은 말 그대로 지연 SQL 결과 접근인데,
DeferredResultSetAccess 객체가 생성되는 시점에는 단지 어떤 SQL을 실행할지 String으로 담아두고, 그 SQL에 대한 결과를
담아 둘 그릇(ResultSet)을 만들어두는 것이다. 그래서 위 코드의 필드를 보면 finalSql, ResultSet이 있는 것을 볼 수 있다.
참고로 ResultSet이란 것은 JDBC가 실행한 SQL의 대한 결과를 의미한다.
JDBC는 SQL을 실행해달라고 요청을 받으면 SQL을 실행하고 그 결과를 ResultSet 타입으로 리턴해준다.

다음으로 생성되는 JdbcValues의 경우 resolveJdbcValuesSource라는 메서드로 생성이 되는데,
조회 결과인 ResultSet(deferredResultSetAccess)과 매핑 정보를 가지고 있는 객체라고 한다.

다음으로는 RowReader라는 것을 생성한다. 이 RowReader가 여러 가공 객체들을 이용해서 SQL의 결과를 객체로 매핑한다.
그렇기에 RowReader를 생성할 때 파라미터로 jdbcValues, executionContext들이 전달된다.
(참고로 domainResult는 jbdcValues에 담아져있음.)
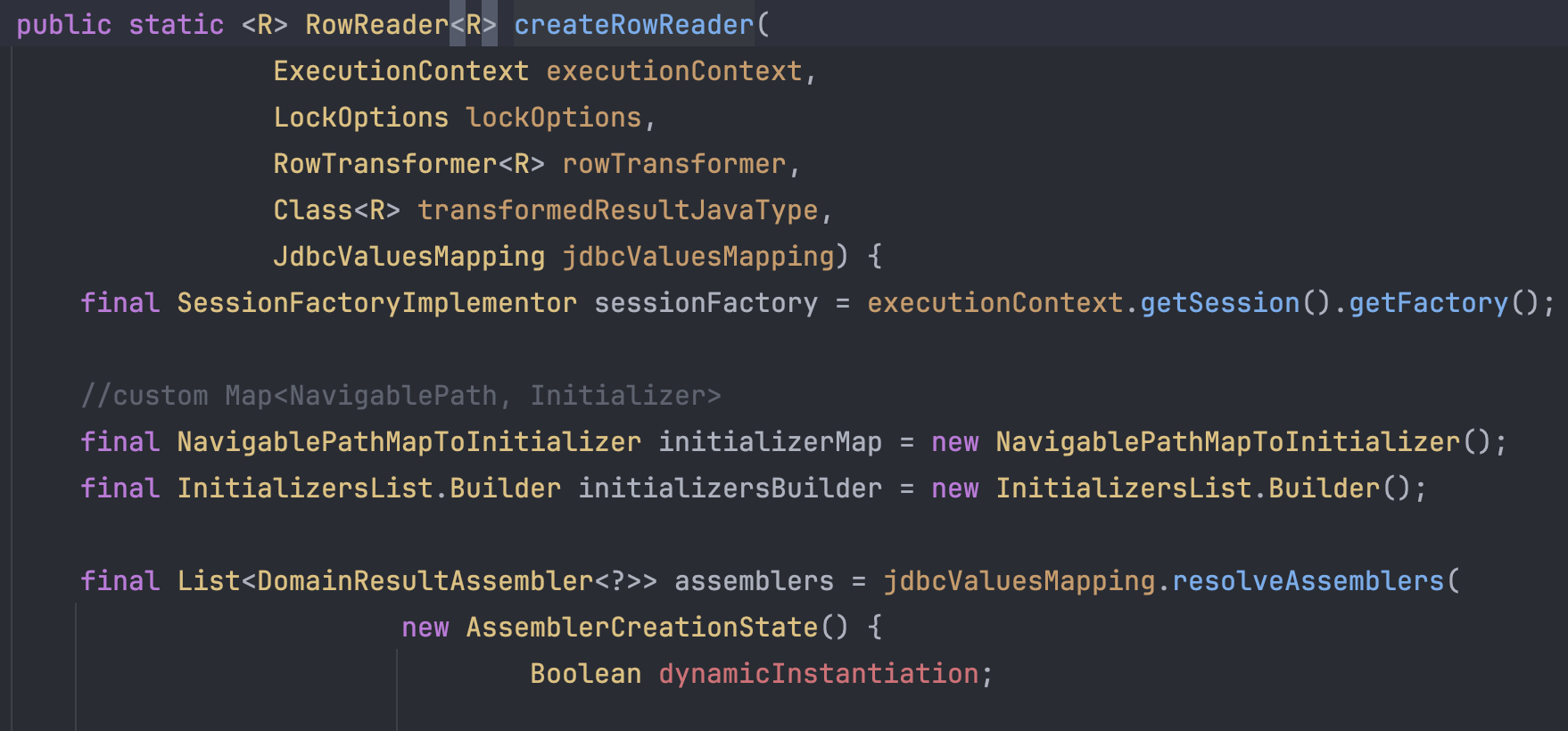
RowReader를 만드는 과정을 좀 더 깊숙하게 들어가보면 DomainResultAssembler라는 객체를 만드는 과정을 볼 수 있다.
DomainResult는 Entity 필드에 대한 정보라고 했는데 그렇다면 DomainResultAssembler는 무엇일까?

DomainResultAssembler는 인터페이스인데 주석을 읽어보면 SQL 결과로부터 데이터를 뽑아내고 조립하는 역할이라고 한다.

위 코드는 DomainResultAssembler를 만드는 과정이다. createResultAssembler 메서드를 호출해서 만드는 것을 볼 수 있는데
만드는 것을 domainResult에게 위임한다. Entity 전체를 조회하는 경우는 domainResult가 EntityResultImpl였다.

위 코드는 EntityResultImpl의 createResultAssembler의 메서드이다. EntityAssembler라는 객체를 만들어주는 것을 볼 수있다.
EntityAssembler는 DomainResultAssembler의 구현체이며, Entity 전체를 조립하기 위한 도구이다.
그런데 resolveInitializer라는 메서드를 호출하면서 무언가의 작업을 진행한다.
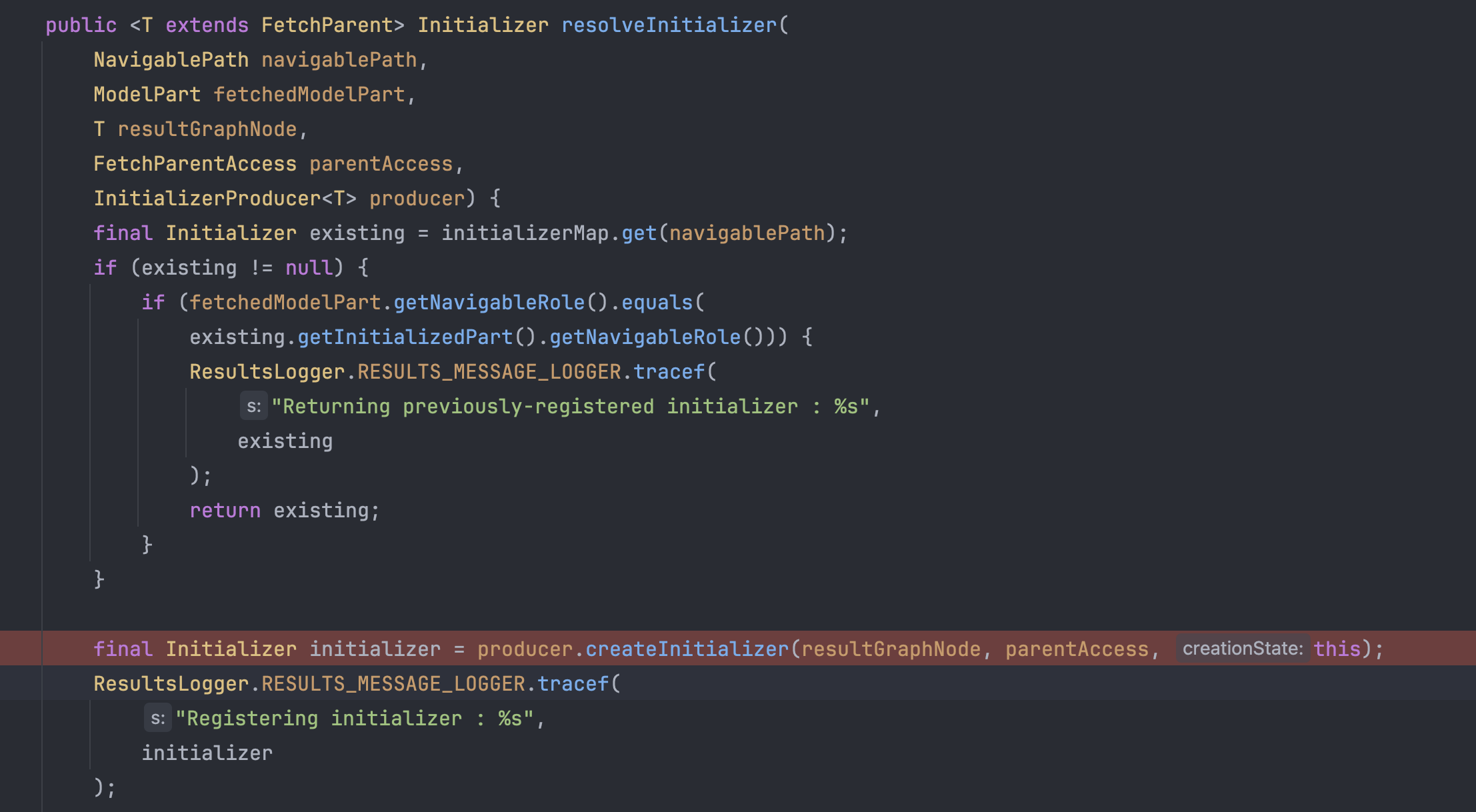
위 코드가 resolveInitializer인데, 이게 좀 복잡하다. 사실 위에서 만들어지는 EntityAssembler가 조립을 처리하는게 아니다.
Initializer들이 처리한다. Initializer라는 것은 Assembler처럼 데이터를 추출하고, 조립하는 역할을 한다. 하청 느낌이다.
만약 여러 Embedded 혹은 연관관계와 같이 Entity에 하위 객체들이 있다면 그 하위 객체들을 조립하는 Initializer들이 생성된다.
Initializer들이 하위 조각(객체)를 조립했으면 최종적으로 EntityAssembler가 이 조각을 합쳐서 최종적인 Entity 객체를 만든다.
이러한 Initializer도 DomainResult가 가지고 있는 InitializerProducer로부터 만들어진다.

그래서 최종적으로 만들어지는 Initializer를 확인해보면 2개의 Initalizer가 만들어진 것을 볼 수 있는데
하나는 Embedded 객체를 위한 Initializer 그리고 Entity 내부 필드를 조립하는 Initializer 2개임을 볼 수 있다.
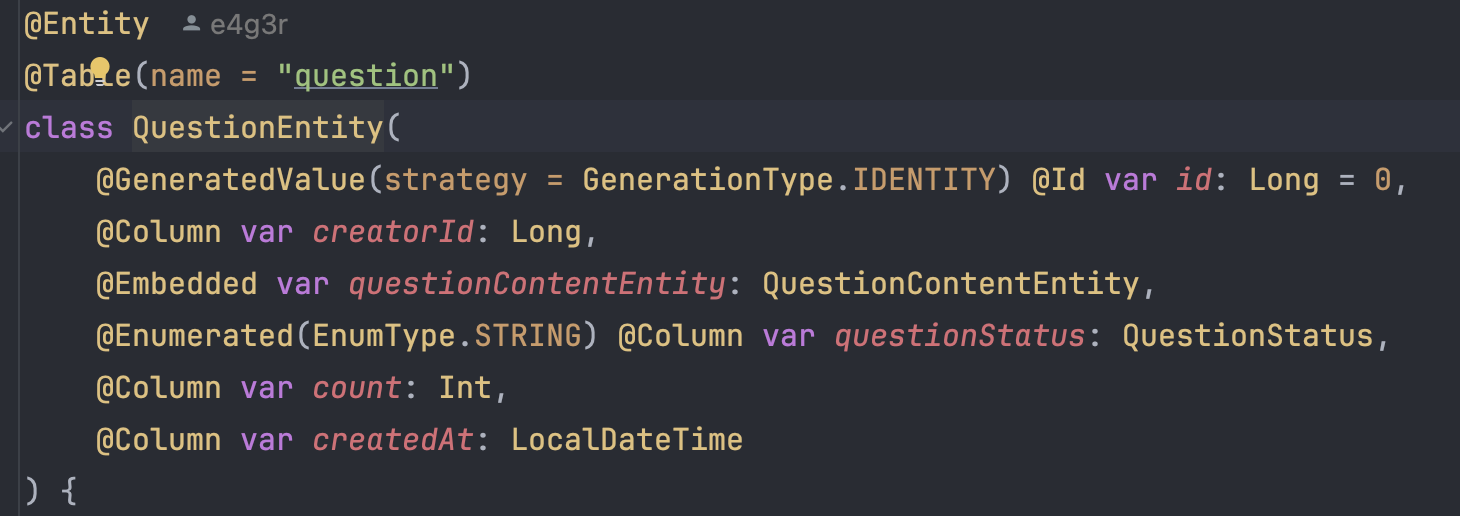
디버깅 과정에서 조회하고자 하는 QuestionEntity는 내부에 Embedded 필드가 있기 때문이다.
만약에 Embedded가 없었다면, 단순히 QuestionEntity를 조립하는 Initializer 1개만 있었을 것이고,
5개의 Embedded가 있었다면 5개의 Initalizer가 더 추가되었을 것이다.
참고로 위 내용들은 모두 Entity 전체를 조회하는 경우에 해당되는 내용이다.
만약 Entity 전체를 조회하는게 아니라, Querydsl을 사용하거나, JPQL로 특정 필드만 조회하여 별도의 DTO로 조회하는 경우에는
각 필드마다 DomainResultAssembler가 별도로 생성되고 다른 방식으로 객체가 조합된다. 이 부분은 아래에서 확인해보겠다.
지금까지의 내용을 간단하게 정리해보자.
DomainResultAssembler -> 정의로는DB로부터 조회한 데이터를 뽑아서 조립하는 역할을 함.
때로는 단순히 ResultSet으로부터 데이터를 뽑아오는 역할만을 할 수도 있음.
Initializer -> 실질적으로 조립하는 실무자임. Embedded, 연관관계 같은 하위 객체들도 조립하는 역할을 가짐.
내부적으로 Assembler를 가지고 있으며, 어떻게 객체를 채워야 하는지 알고 있음. 근데 사실 Initializer가 다 하는건 맞음.
DomainResultAssembler는 이미 Initializer가 만들어둔걸 그냥 반환만 해주는 역할임.
이어서 가보자.
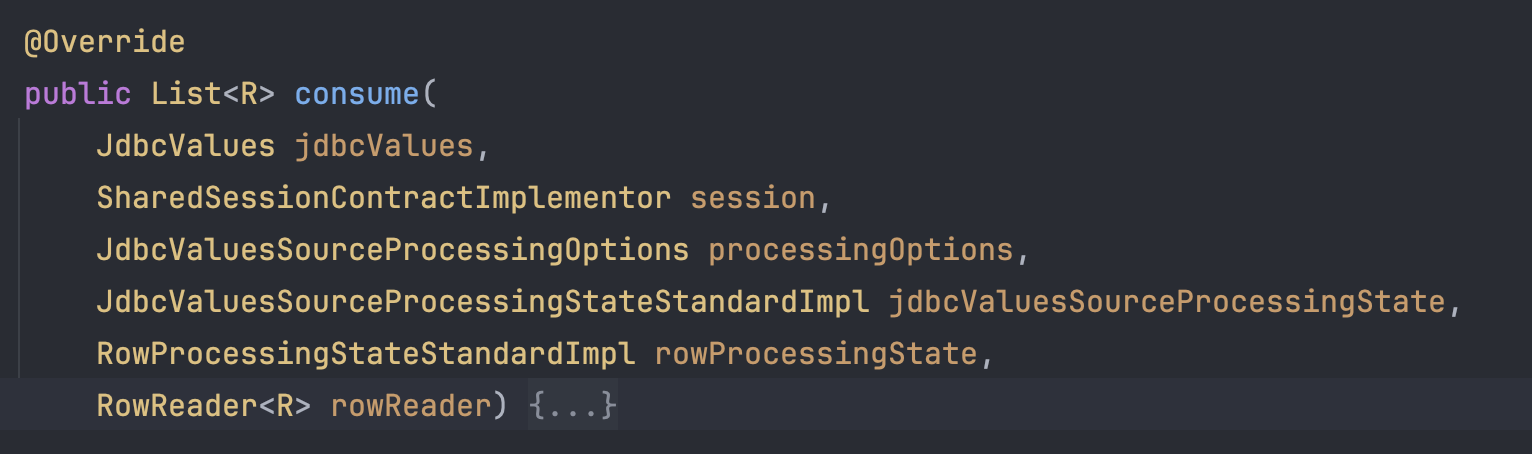
이후 ListResultsConsumer.consume 메서드를 만나게 된다.
이 consume 메서드가 최종적으로 JDBC에 SQL을 요청하고, 필요로 하다면 Entity로 매핑까지 처리하는 메서드이다.
따라서 앞서 만들어둔 jdbcValues, rowReader를 파라미터로 받는다.

consume 메서드의 핵심 부분이다. next 메서드는 cursor 기반인 ResultSet을 순회하는 부분이다.
예를 들어 Select를 했을 때 조회된 Row가 100개라면 ResultSet은 cursor 기반으로 동작하기에 한 행을 읽을 때 마다 next를 호출 해
데이터를 조회해야한다. 만약 더이상 읽을 Row가 없다면 false를 반환할테니, ResultSet은 끝날 것이다.
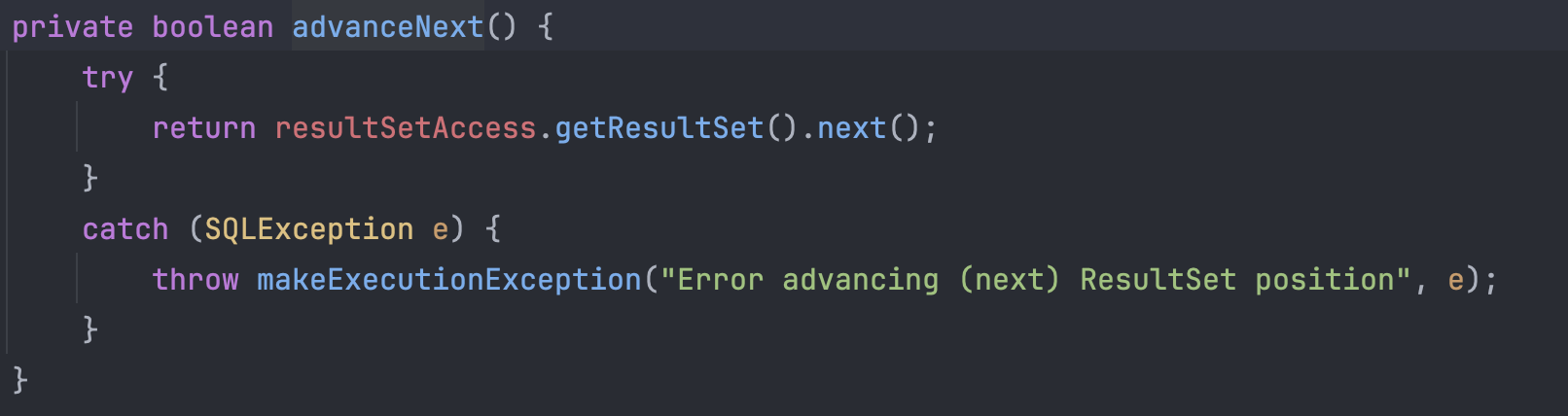
재밌는 건 next 메서드를 디버깅하면서 쭉 따라가면 위에서 만들었던 JdbcValues의 advanceNext를 만나게 되고 여기서DeferredResultSetAccess에 접근하게 된다.

만들어두었던 ResultSet은 이름 그대로 지연ResultSet이기에 첫번째 next의 경우는 아직 SQL이 전송되지 않은 시점이다.
따라서 값이 없다면 JDBC를 통해 SQL이 전송된다.
여기까지가 JPA + Hibernate가 JPQL을 SQL로 변환해서 JDBC로 SQL을 요청한다음 JDBC가 주는 결과인 ResultSet을 전달받는
과정이다. 이제는 매핑의 차례이다.
Hibernate의 매핑

매핑은 next로 커서를 움직여서 데이터를 가져오고 앞서 만들어둔 rowReader를 통해 데이터를 읽는다.
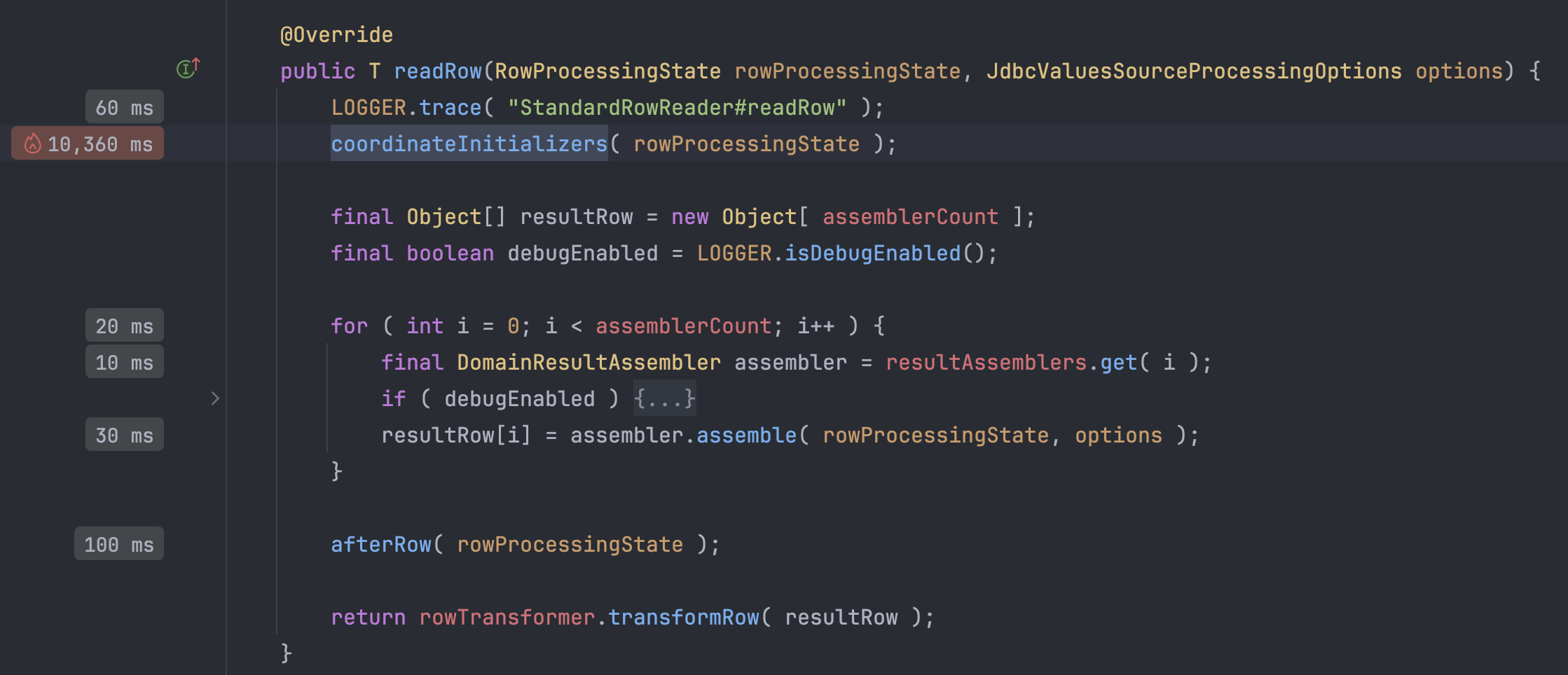
먼저 Hibernate에서 기본적으로 Entity를 매핑할 때는 rowReader의 구현체로 StandardRowReader가 사용된다.
readRow 메서드 초기에 coordinateInitializers가 호출되는데 사실 매핑은 여기서 끝난다.
병목 지점이 매우 핫한거만 봐도 알 수 있다.

coordinateInitializers 메서드 내부를 보면 3개의 Initializer 메서드가 호출된다.
Initializer는 앞서 만들어둔 Initializer들이다.

먼저 resolveKeys를 처리하는 Initializer는 Key와 관련된 필드를 초기화한다. 흔히 PK 혹은 연관관계의 키를 설정하는 단계이다.

다음으로는 resolveInstance를 처리하는 Initializer인데, 결과로 반환 될 Entity 객체를 기본 생성자로 생성해주는 부분이다.
그래서 PK와 같은 값은 채워지지만 나머지 값들은 null과 같은 값으로 채워진다.

다음으로는 Entity 클래스의 남은 필드들을 ResultSet으로부터 데이터를 뽑아오고 채워주는 Initializer 부분이다.
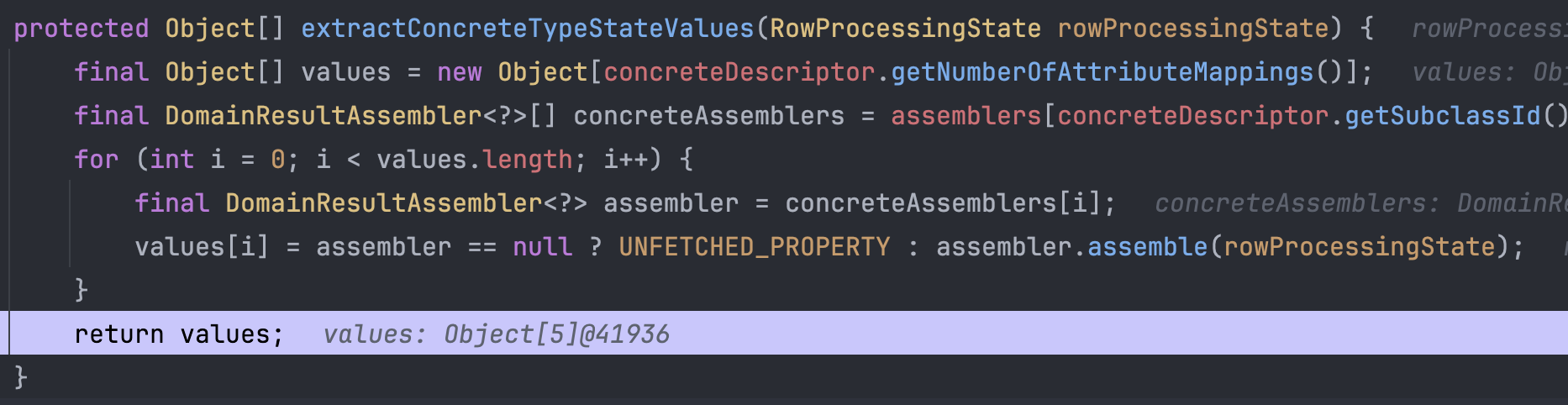
Initializer는 결국 Entity 조각을 채우기 위한 조립 실무자라고 했다.
따라서 내부적으로 자신이 가지고 있는 DomainResultAssembler를 이용해서 ResultSet으로부터 데이터를 뽑아온다.

ResultSet으로부터 뽑아온 데이터인 values를 디버거로 확인해보면 실제로 채워야 할 5개의 데이터가 담아져있음을 볼 수 있다.
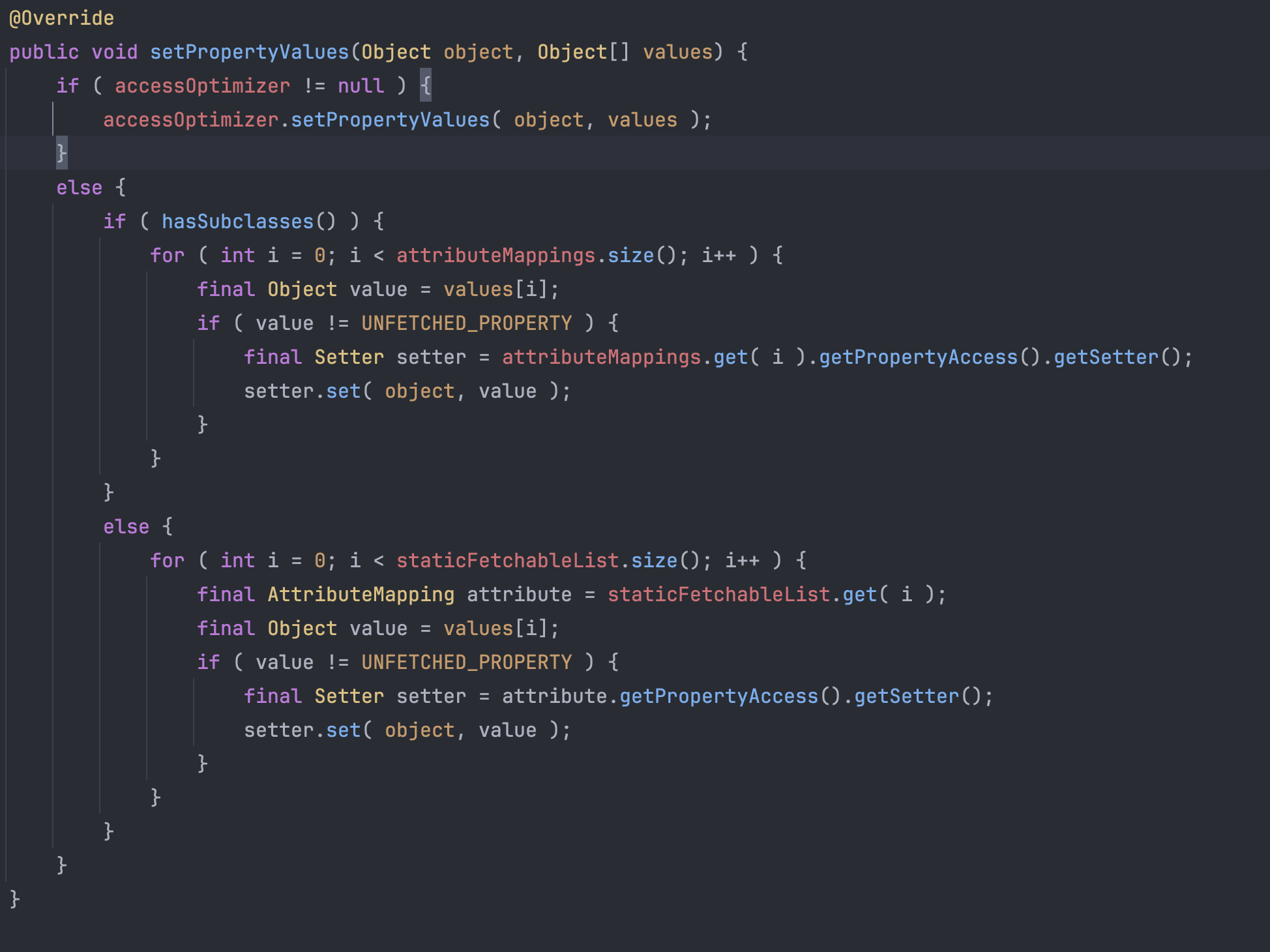
그리고 위에서 쪼갠 데이터들을 순회하면서 특수한 setter로 데이터를 채워넣으면서 조립한다.

staticFetchableList 내부에는 채워넣어야 할 QuestionEntity 필드들이 있고 그걸 하나씩 돌면서 데이터를 채워 넣게 된다.

그럼 위에서 말했던 것처럼 하청 작업자 Initializer가 마무리 되었으니 최종 책임자인 Assembler가 조각들을 합친다.

Assembler가 조각들을 합치게 되면 결국 조회하고자 했던 QuestionEntity 클래스가 만들어지게 된다.
여기까지가 Hibernate의 매핑이다. 복잡하다.
특정 필드만 조회하는 경우의 매핑

만약에 전체 Entity를 조회하는 것이 아니고 특정 필드만 DTO 클래스로 조회하는 경우에는 어떻게 동작을 하는지 살펴보자.

위에서 보았던 과정들을 똑같이 진행했을 때 생성되는 domainResult를 보면 5개다.
현재 조회하고자 하는 필드는 5개이다. 따라서 필드마다 domainResult가 생성되었다.
Entity 전체를 조회하는 경우에는 EntityResultImpl이라는 DomainResult 구현체가 사용되었지만, 지금은 BasicResult라는
구현체가 사용되고 있다.

그리고 Entity 객체 전부를 조회할 때에는 Assembler를 만드는 과정에서 Initializer를 만들었었다.
하지만 BasicResult는 Initializer를 만드는 과정없이 단순히 BasicResultAssembler만 만든다.

RowReader를 만드는 과정에서 생성되는 Initializer는 1개도 없으며, 단순히 각 필드에 대한 DomainResultAssembler만 만들어진다.

StandardRowReader에서 initializer를 호출하면서 Entity의 키 초기화, 인스턴스 초기화, 나머지 필드 채우기를 처리했던 부분도
아무런 initializer가 없기에 그냥 넘어가게 된다.
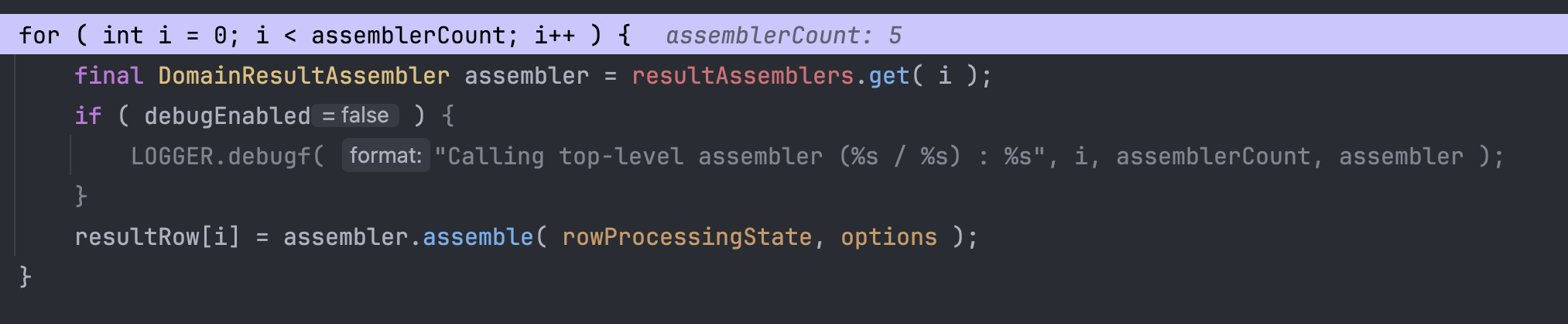
Entity를 전체 조회할때에는 1개의 EntityAssembler만 있었기에 그냥 initalizer가 만들어두었던 조각들을 합치는 역할만 했다면,
지금은 5개의 BasicAssembler가 각각 데이터를 불러온다.
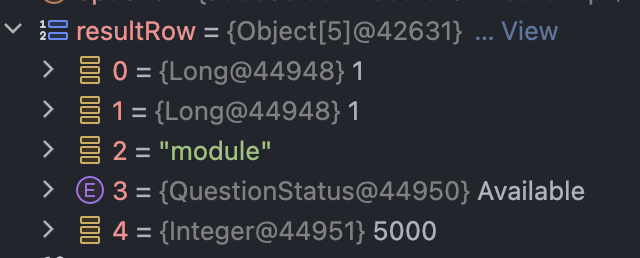
Entity 전체를 조회하는 경우에는 최종 Assembler를 거치면서 resultRow가 QuestionEntity 타입이였지만,
지금은 단순히 Object 배열의 형태이다. 따라서 그냥 이 Object 배열 상태로 반환된다.

querydsl의 흐름을 살펴보면 query.getResultList() 부분이 JPQL 실행 결과를 전달받는 부분이다. 따라서 Object 배열을 받는다.
querydsl의 Projections을 사용하는 경우에는 생성자를 파라미터로 넘기기에 전달받은 파라미터 기반으로 알아서 Object를 가공해서
객체를 생성해주는 것이다.
한마디로 Querydsl의 Projections을 사용하는 경우에는 객체 생성을 어찌보면 Querydsl이 해주는게 맞긴하다.
Hibernate는 단지 JDBC의 ResultSet으로부터 필드를 분리해서 Object 배열로 넘겨주기만 할 뿐이다
마무리
결론은 Entity를 조회할 때마다 매핑할 객체의 정보를 매번 분석하는게 아니라, 미리 만들어둔 메타 정보를 이용하기에,
그렇게 큰 오버헤드를 발생하지 않는다. 애초에 이미 너무 잘 되어있고, 더 튜닝할 부분도 없다고 생각된다.
이렇게 잘 되어있는 Hibernate의 매핑 성능이 부족하다고 느끼기 힘들 것이다.
그리고 Hibernate는 이렇게 빠른데 왜 Spring Data Mongo는 기본 매핑이 그리 느린가에 대해서도 정리해야하는데
hibernate를 건드리다가 시간이 너무 많이 소요되었다. 이는 다음에 봐야겠다.
추가로 디버깅 과정도 그렇고 너무 호출되는 흐름이 복잡해서 분석하는데 너무 많은 시간이 걸렸다.
그래서 사실 위 디버깅 결과들도 그리고 정리한 내용도 거의 추측 + 검색 + 디버깅 반복으로 나온 결과라 정확한지도 모르겠다.
요약
1. Hibernate가 미리 Entity 클래스를 순회하면서 만들어둔 메타 정보를 만들어둔다
2. JPQL을 해석해서 어떠한 데이터를 조회하는지 분석하고, 만들어둔 메타 정보를 이용해서 매핑 정보를 만든다.
3. 매핑 정보를 통해 SQL 결과를 원하는 형태로 가공할 수 있도록 하는 매핑 도구를 만든다.
4. JDBC를 통해 SQL을 요청하고 ResultSet 형태로 받는다.
5. ResultSet을 순회하면서 매핑 도구를 통해 객체를 생성한다.
결로: 미리 메타 정보를 만들어두었기에 매 요청마다 Entity 객체를 분석할 오버헤드가 없다.
'spring' 카테고리의 다른 글
| Spring Data Mongo 매핑 최적화 with Kotlin Serialization, kbson (0) | 2025.11.27 |
|---|---|
| @Transactional의 오버헤드 (0) | 2025.10.21 |
| [Spring] @Transactional의 동작 과정 (feat.EntityMangaer, OSIV) (3) | 2025.06.04 |
| [Spring] doDispatch 예외 처리 (1) | 2025.06.02 |
| [Spring] JPA @Id 생성을 직접 하는 경우 isNew() 오버라이딩 (0) | 2025.05.22 |